
Fine Line in AI Applications: Trivial or Tool
Why accuracy thresholds define AI adoption

Wrote a slightly nuanced piece a while back on how to separate AI tool as “thin-wrappers” or real defensible value drivers. (link)
Only to conclude it can be understood in a much simpler way
This framework is way too complex ↓

AI applications do often make us go “wow”, but adoption of these products is the biggest metric.
“Wow” leads to → Multiple pilots / customer trials / signups but very limited retention or engagement of the actual product.
AI That Impresses ≠ AI That Works
And AI applications can be put into two broad categories:
It’s either a toy or it’s a tool
Most people look at AI applications and say: “It’s already 90% accurate, that’s pretty good!”
But the truth is: In most real-world workflows, 90% doesn’t work.
It is why performance benchmarks in AI really matter more than you think.
In fact, even 95% may be useless — unless it crosses a certain threshold for that use case. Here are a few real examples:
1. Coding with AI (90% accurate) replacing programmers (currently):
Even if the model writes 90% of the code correctly, the developer still has to read, understand, and debug the rest — which means they already need to fully understand what the code is doing.
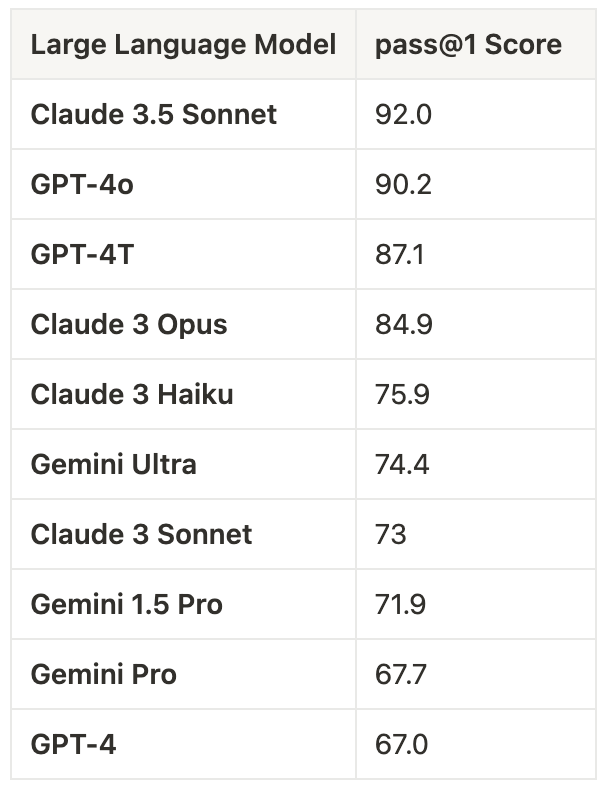
Key benchmarks include HumanEval, SWE-bench, and Codeforces
So you’re saving time, but are you?
You end up just reviewing and rewriting someone else’s logic.
So actually reducing a hours here and there but not replacing
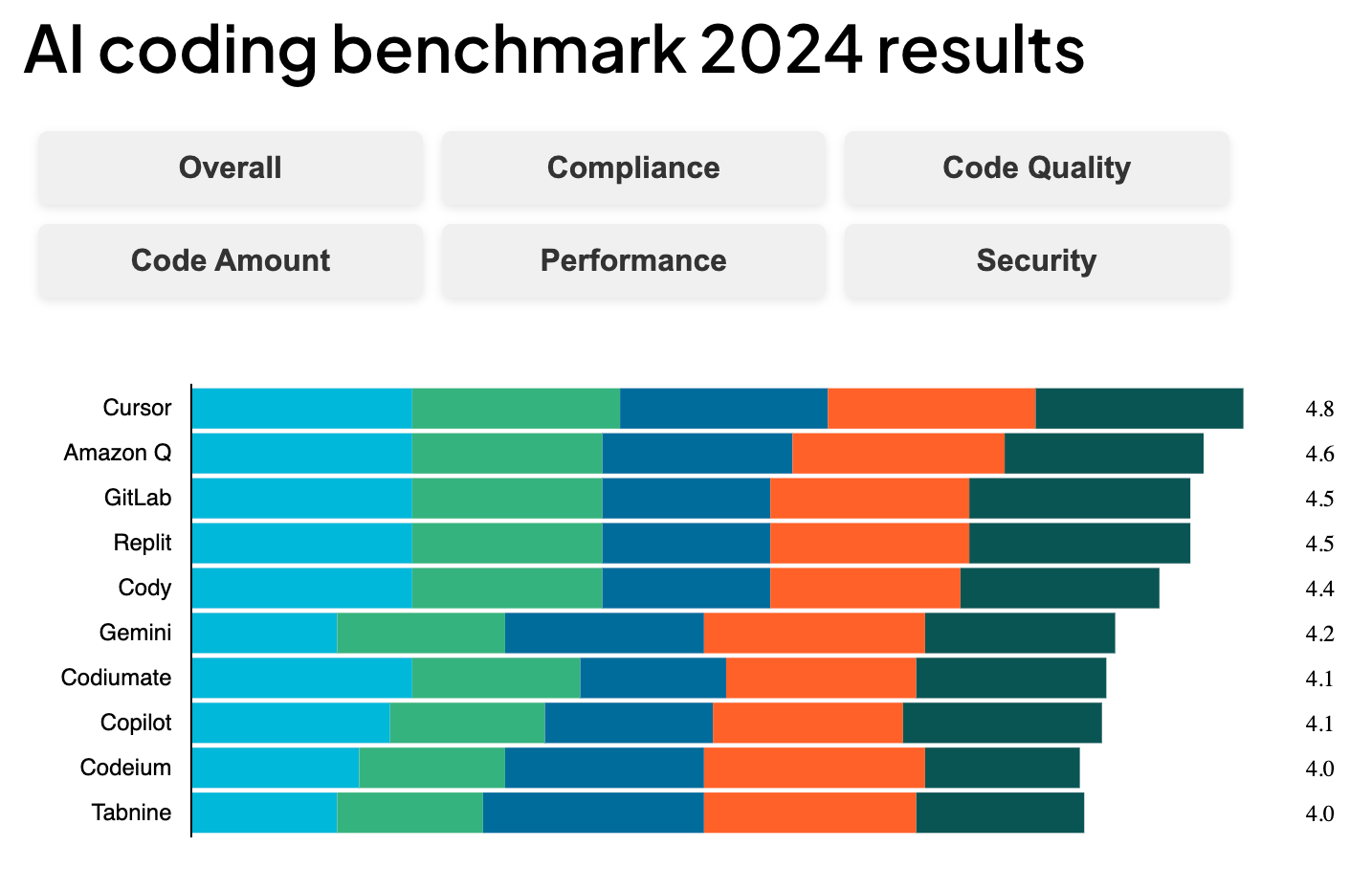
Updated at 02-17-2025
2. Content generation (95% accurate):
AI writes a 2-page memo or report. I still have to read every line, understand the logic, or correct the tone. If it takes 5 minutes to generate (prompt time included) and 10 minutes to fix — that’s 15 minutes. One (average writer) can write ~ 2 pages in 15 minutes.
Hence using AI to write only makes sense if you are writing 3 pages or more in this example and complex uses cases are usually not covered.
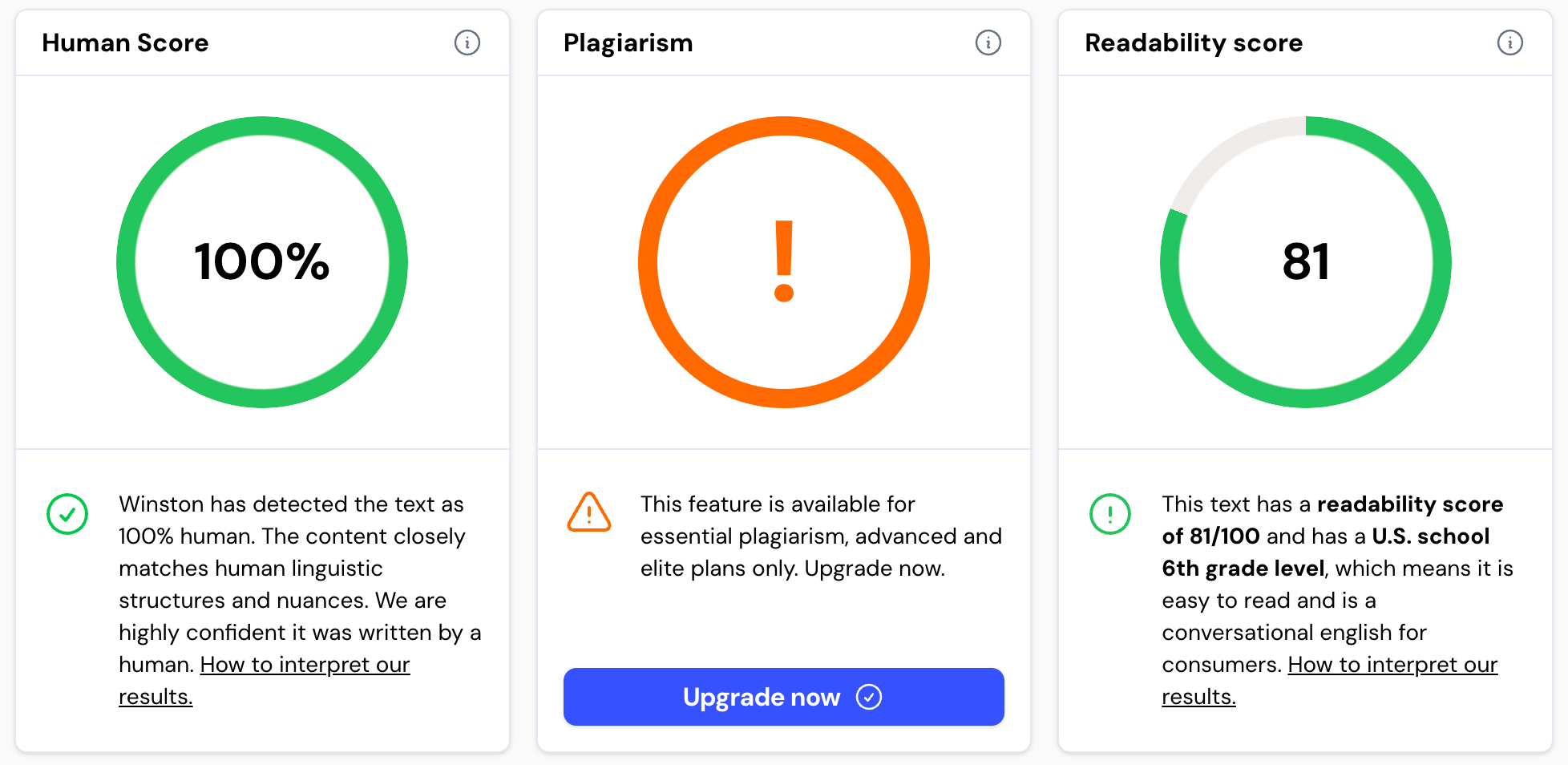
Say for all this content of this post :
I have written to the level of a 6th grader 😂, but much faster than AI generation and then correcting the whole thing + relevant images.
Picture from analysing this post through Winston AI (https://gowinston.ai/)
3. AI for customer support (98% accurate):
Sounds great — until you realize the 2% failures are all angry customers who get the wrong resolution at the worst time.
That 2% = churn, PR risks, lost NPS = loss of trust. That margin of error is unacceptable.
Hence most AI customer support workflows are human augmented to address such issues.
Common AI Failure Modes in Customer Support
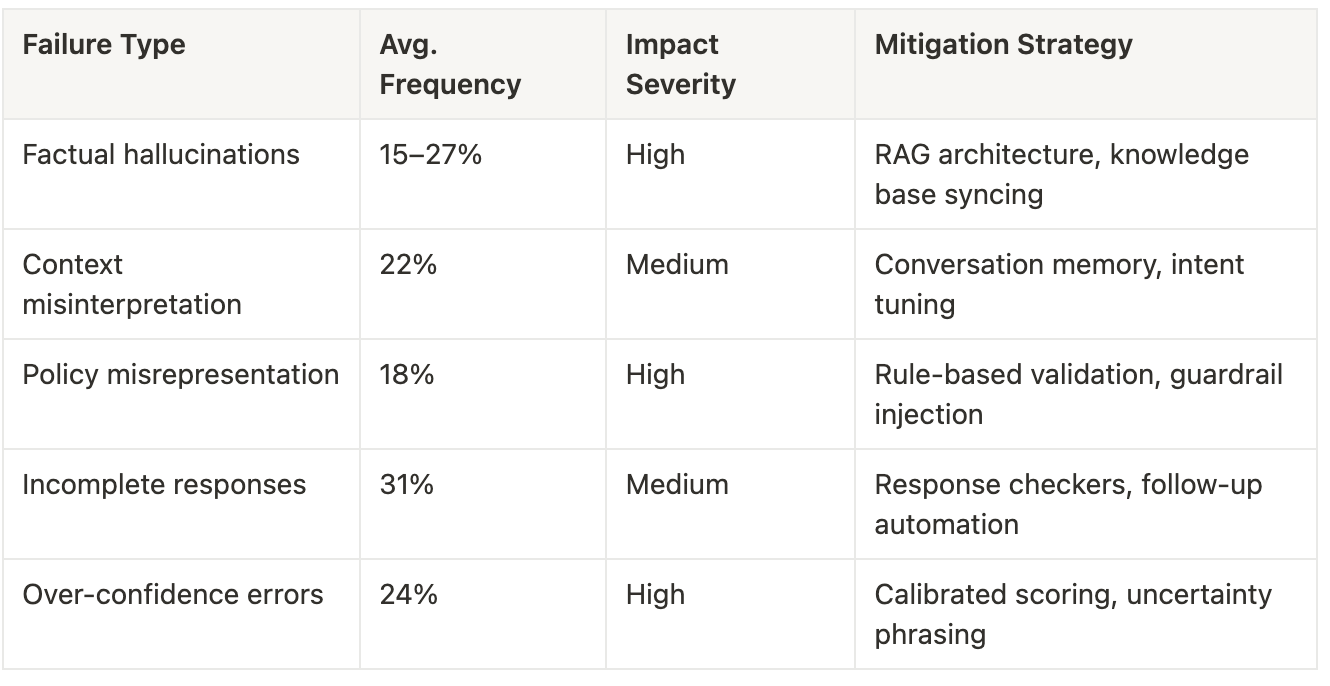
Error Rates by Interaction Type

AI Chat support leader: Intercom
Voice AI outbound / support: Squadstack.ai or Toma (a16z funded) trying to do it horizontally in various categories.
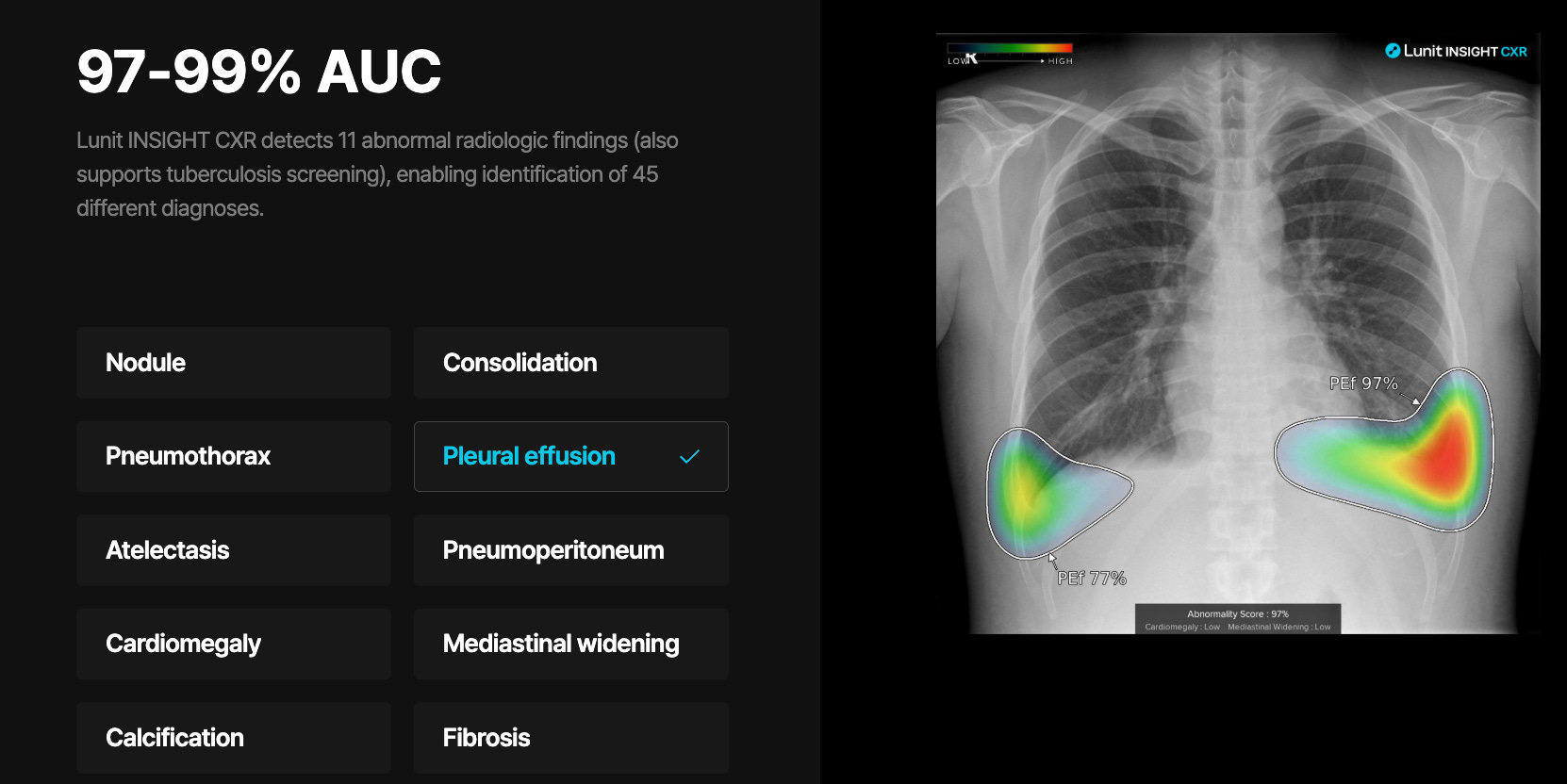
4. Medical diagnostics (99% accurate):
Still not enough. Would you trust an MRI scan summary that’s “only wrong 1% of the time”?
In life-critical scenarios, you don’t need good enough — you need something closer to 100% or bust.
AI in radiology (most advanced in terms of the AI applications) works when augmented with actual radiologists having to confirm each and every scan
Qure.ai, Lunit etc. are trying challenge the impossible, and Radiology AI foundational models might make them obsolete.
5. Examples where AI adds value even at lower accuracy:
Speech-to-text for meeting notes (~85%): Doesn’t need to be perfect — just needs to capture the gist. Humans can glance and extract action items.
Fathom.video is one such tool which I love and how it works for me.
My workflow: Fathom (transcribing) → Zapier (trigger & connection) → Notion (notes from calls)
Product image upscaling or background removal (~80%) Tools like Pixelcut or Remove.bg don’t need to be perfect every time. If 8/10 images are good enough, it already saves hours of manual Photoshop work.
The insight:
AI isn’t just about getting “better.”
It’s about crossing the performance threshold where human trust and workflow efficiency kick in.
Below that, it’s a toy. Above that, it’s a tool.
The question “how good / accurate is this model?” is a vague and futile one.
What makes sense to ask: “Is it accurate / performing enough for the user to trust it without checking it end-to-end?”
That’s when real flood-gates for AI adoption open.
How does one identify these thresholds? What will work & what wont ?
Amazing article!