
How to make your own LLM → ChatGPT ?
An all-you-need guide :P

Taking inspiration from freely available Llama LLM model.
An LLM model (say Llama 2 - 70b), has just 2 files:
Around 500-1000 lines of code.
Parameters file: 70 billion weights (140GB in size, each parameter stored as 2 bytes)

There are only 3 steps of getting your own ChatGPT :
Write / copy the lines of code (much openly available Llama 2-70b code)
Here is the link for you to download the code :- https://huggingface.co/meta-llama/Llama-2-70b-chat-hf/tree/main
Pre-Training
Fine-Tuning
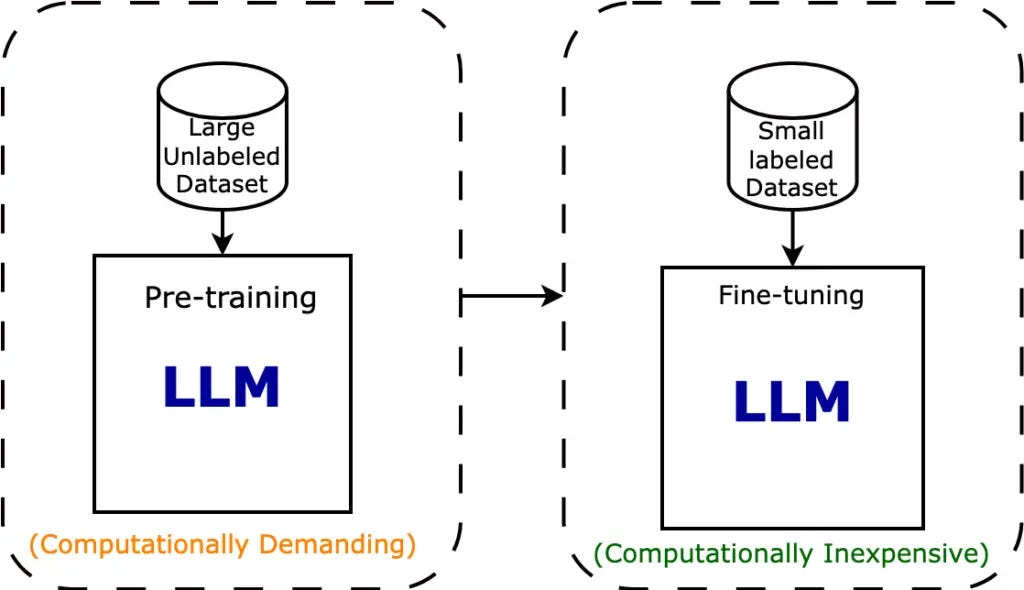
Pre-Training gives in pre-trained weights which are mostly frozen and are layered with trainable weights which result from fine-tuning the model using labelled data

Stage 1: Pre-training
(Done at very low frequency ~ once / year or once / quarter)
Think of it as compressing the internet into a smaller format.

Download ~10TB of text from the internet
Get a cluster of ~6,000 GPUs to process / compute and process it.
Compress the text into a neural network, pay ~$2M, wait ~12 days.
Obtain base model.
Stage 2: Fine-tuning
Think of it as swapping the data on which the model is trained with manual input data and re-training the model - done to get more contextual alignment.


Write labeling instructions
Supervised learning: Hire people, collect ~100K high quality ideal Q&A responses, and/or comparisons.
Fine tune base model on this data, wait ~1 day, around $100K - $300K in costing
Obtain assistant model.
Run a lot of evaluations.
Deploy.
Monitor, collect misbehaviors, and go to step 1.
Other than all this, you need access to GPUs + $8-10 million to start training, post that, all the luck you can get.
Hope you learned something interesting, and are charged up to train your own LLM in no time 😂
Please fell free to share if you have any inputs / feedbacks. I’m at saharsh@oriosvp.com